【数据分析与预处理】 ---- 数据的提取与筛选
本文共 827 字,大约阅读时间需要 2 分钟。
文章目录
1.读取数据
data = pd.read_csv("G:\Projects\pycharmeProject\大数据比赛\data\mysql.csv")print(data.shape) 2.数据的提取与筛选
2.1 增加某一列
2.1.1 以原数据的索引添加列
data['index'] = data.index
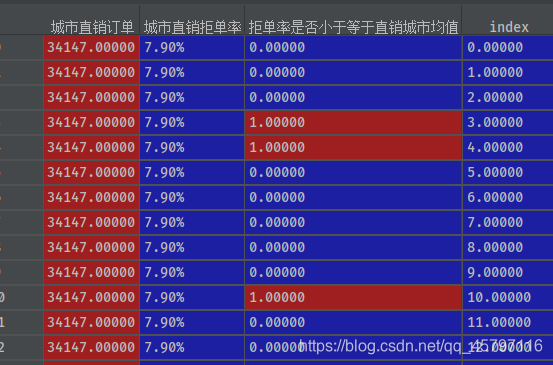
2.1.2 以国家数据添加列
data['country'] = data['国家']
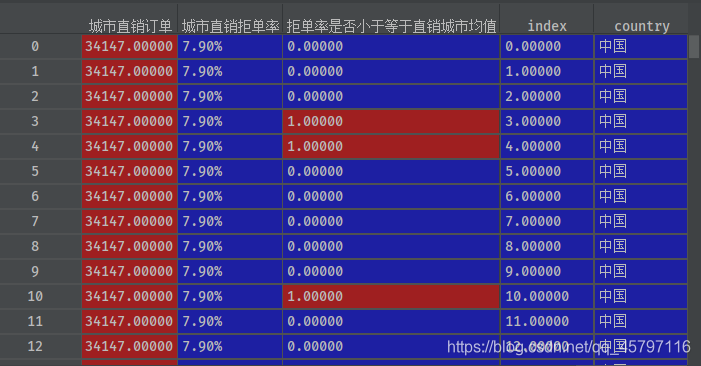
2.2 删除特定列 drop(columns=’?’)
data_drop = data.drop(columns='index')
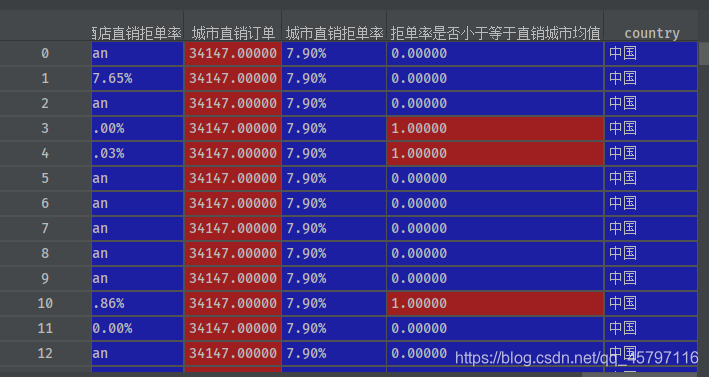
2.3 删除特定行 — 根据索引删除 drop(index=[?],axis=1)
data_drop_index = data.drop(index=1,axis=1)data_drop_mulIndex = data.drop(index=[1,2,3,4,5],axis=1)
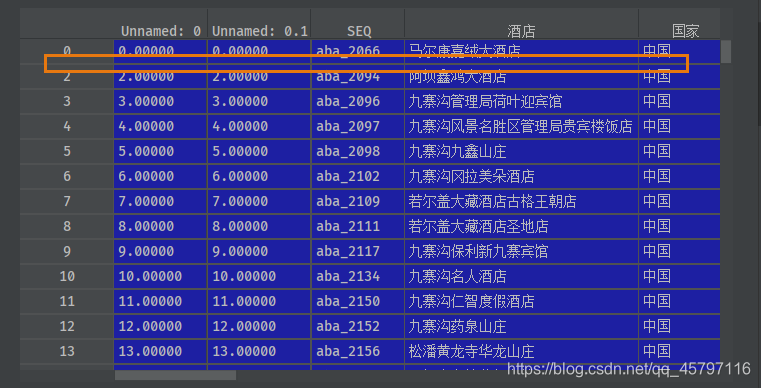
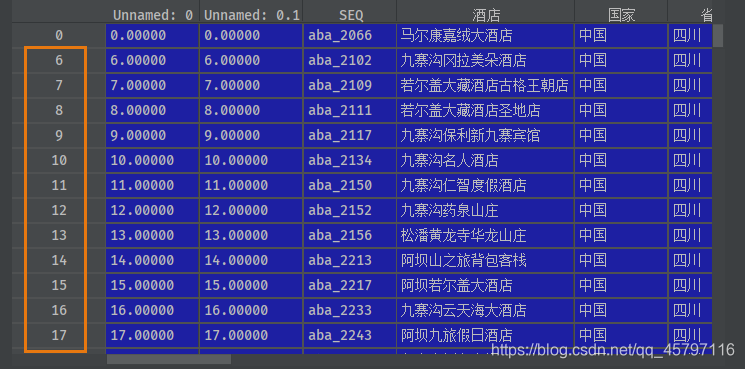
2.4 删除特定值的记录
2.4.1 找出特定值所在行进行筛选
方法一 drop(index=data_target_index,axis=1)
data_condition = data['城市'] == '阿坝'data_target = data.loc[data_condition]data_target_index = data_target.indexdata_drop_target_index = data.drop(index=data_target_index,axis=1)

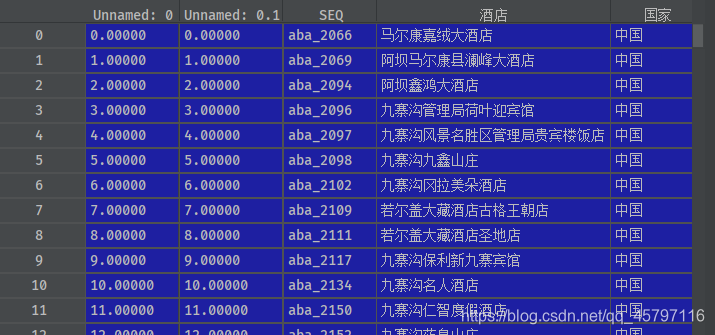
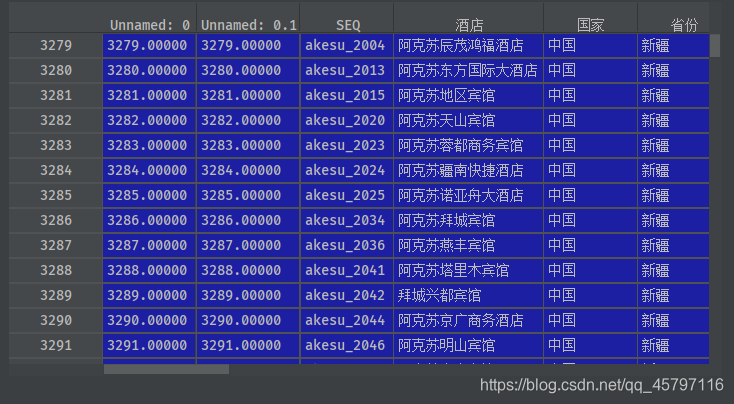
方法二 loc[~data_condition]
data_condition = data['城市'].isin(['阿坝'])data_target = data.loc[data_condition]data_without_target = data.loc[~data_condition] # 加个~号

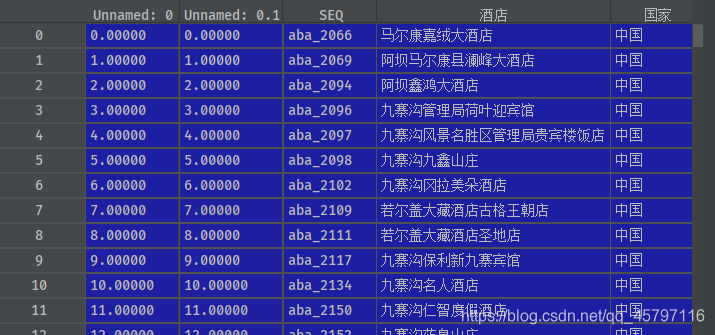
转载地址:http://bzeq.baihongyu.com/
你可能感兴趣的文章
Neo4j安装部署及使用
查看>>
Neo4j电影关系图Cypher
查看>>
Neo4j的安装与使用
查看>>
Neo4j(2):环境搭建
查看>>
Neo4j(4):Neo4j - CQL使用
查看>>
Neo私链
查看>>
NervanaGPU 项目使用教程
查看>>
Nerves 项目教程
查看>>
nessus快速安装使用指南(非常详细)零基础入门到精通,收藏这一篇就够了
查看>>
Nessus漏洞扫描教程之配置Nessus
查看>>
Nest.js 6.0.0 正式版发布,基于 TypeScript 的 Node.js 框架
查看>>
nested exception is org.apache.ibatis.builder.BuilderException: Error parsing Mapper XML.
查看>>
nestesd exception is java .lang.NoSuchMethodError:com.goolge.common.collect
查看>>
nestJS学习
查看>>
net core 环境部署的坑
查看>>
NET Framework安装失败的麻烦
查看>>
Net 应用程序如何在32位操作系统下申请超过2G的内存
查看>>
Net.Framework概述
查看>>
NET3.0+中使软件发出声音[整理篇]<转>
查看>>
net::err_aborted 错误码 404
查看>>